
By now, most of us are using Frontier Models at work and at home. But we are uncomfortable with data leaks, privacy and the cost of APIs. What happens when you download and install your own model? In a few steps, you can run a Small Language Model (SLM) directly on your laptop instead of in some far-off data center. It’s faster, cheaper, and keeps your data exactly where it belongs: with you. We explore how anyone can download, install, and connect an open-source model to their own data, gaining control and redefining its guardrails. The future of AI is local, efficient, and personal. Get unchained.
Fiona Passantino, AI Leadership
With many thanks to Nicolò Turri
Today, I have my very own baby LLM running on my MacBook. No data is sent to a whopping datacenter in Shanghai or Nevada. I can use it on a plane. I can query on a train. I can ask it anything; how to build a meth lab in my house, to create a rap song comprised entirely of profanities or advise me on how best to traffic illegal wildlife across borders. It will cheerfully comply. I can feed it whatever information I want, as none of my data leaves my desktop.
It’s entirely unchained, and it’s all mine.
How did this happen? With the help of a patient, highly technical sherpa, I downloaded an open-source model from one of the big repository environments and installed it, set it up, and ran it. It took about an hour, including the search for a “guardrail-free” variant. Quantized[1] to fit my laptop, the Large Language Model (LLM) became a Small Language Model (SLM), and I had all the inference[2] I needed right at home.
Unchained at Work
Why is this interesting? Aside from the obvious benefits of enthralling my teenaged kids and learning some surprising new swear words, an Unchained SLM has a few obvious business advantages.
- Privacy: your data never leaves your device, so no leaks, no spying, no compliance headaches and no worrying that your interns are playing fast and loose with customer information with the frontier models.
- Speed: with no internet lag or off-site inference, a quantized system is blazingly fast. Responses are nearly instant because everything happens right on your machine.
- Cost: with no API fees or cloud compute to worry about (especially the kind you can’t control), your own SLM is only costing you only electricity and hardware depreciation.
- Reliability: this system works anywhere, even on a plane, in a factory, in front of or behind a firewall. Yes, it will still hallucinate like any other model, and yes, we Humans will still need to employ our skepticism and critical thinking to work with this or any AI model, but glitches and downtime are greatly reduced.
- Customization: as any freshly-minted mom knows, you are entirely responsible for the proper fine-tuning of your baby. Feed it high-quality data, strap it in safely in your environments, and give it the attention and guidance it needs to be a top-performer.

Getting Unchained
So, where do we start? We begin in the tech-heavy underworld of Open Source; an intimidating place to roam as a Non-Technical (there is little care for graphical interfaces or usability in these places, and you need to read a bit of code or changelogs to get around), treasures can be found for those who know where to look.
1. Download an open-source LLM
LM Studio or Hugging Face are websites and desktop apps that run on all platforms, that gives you access to models without coding. These are the often the places where the big players road test their models before release; the small Army of Geeks happily devour them and comment on their performance.
- Open LM Studio and go to the “Discover” tab.
- Search for a model you like; Western ones (Mistral-7B, Llama-2-7B, Gemma-7B), Chinese ones (Qwen, DeepSeek), and many others in between.
- The “B” refers to the number of parameters in a system, often a measure of performance. B = Billion. So, a 7B model will have a 7-billion parameter brain. All the inference you need to make high-quality fart jokes.
- Click “Download”; the platform handles model files (.gguf or.safetensors) Thankfully.
- Find the settings in LM Studio’s model folder. These are raw model weights living on your machine.
2. Install it on your own server
To move beyond the platform’s desktop interface, set up your environment locally. If you want speed (and have the money), go with a Linux server powered by an NVIDIA GPU. If you are a normal person, not engaging in protein folding at home, just copy the weights and install in your applications folder. That’s it.
3. Train it with internal data
There are two good ways to do this depending on your goals and comfort level with tech.
As a power user, fine-tune your model. There are frameworks to employ (like PEFT/LoRA, Parameter Efficient Fine-Tuning) and tools (Hugging Face transformers) to wizard you through the process. Have a Tech Translator next to you for help. You’ll need systems with a lot of memory (at least 24GB for 7B, more for 13B and over).
As a normal Human, embed with RAG (Retrieval-Augmented Generation). This means that, instead of training and changing your new baby, you give it a good way to access your documents. It’s a faster way to get started and keeps the model “pure” for other uses.
Start by indexing your internal documents with embeddings (using sentence transformers or naming conventions). Store your embeddings in a vector database (this will require a bit of assistance from your IT department, but if you buy them a burrito, they will be happy to help). Build an agent interface on top of the pure model and upload the documents you want into this agentic layer. Make sure it has memory and recursive improvement. You’re done: query your model in natural language, asking for information it has access to.
4. Share your model
Once you have used your system a few times and have an established workflow, invite your colleagues to query it safely inside your guardrails. This can be done with the RAG system you set up, or an internal API call from their system to the server.
Building Unchained Systems
As an organization, we are learning how to move from running 100% of our tasks through commercial LLMs (ChatGPT, Copilot, Gemini, Claude, Mistral etc.) to a combination of LLMs and SLMs. The idea is never to stop using Frontier Models altogether but using them for the right kinds of jobs. The big players offer a high level of performance and accuracy; they are thinking on the fly, swimming in their vast lakes of data in their whopping data centers and weaving in access to the live web.
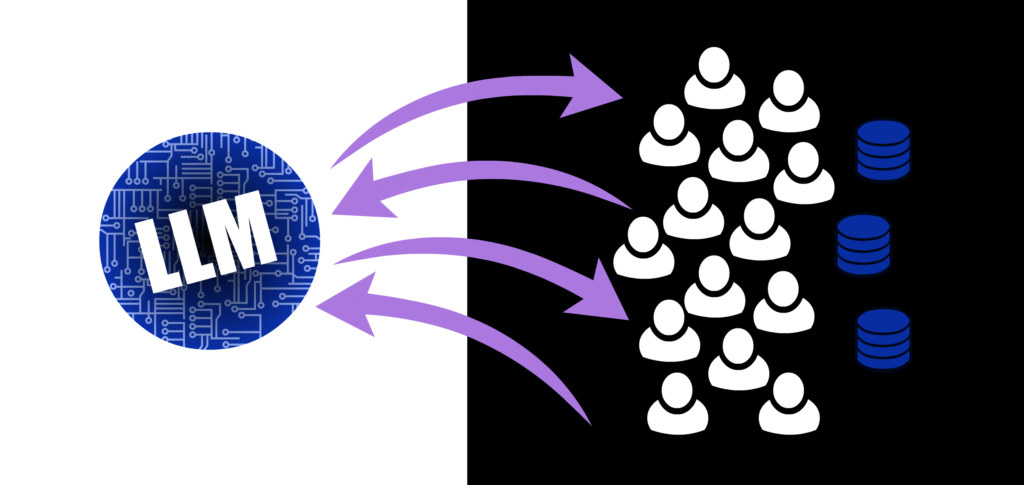
Figure 1: when you use a LLM, you run inference off-site, meaning any data you send it gets tokenized and crunched up in a far-away data center in Milwaukee or North Dakota, always keeping a full version intact for training purposes (but don’t worry, they promise not to use it if you’re a paying customer), and keeping the tokenized version for spare parts.
Once there is a single SLM in place at your organization, residing on your own local machine, you create a safe environment for sensitive inference. You may notice a dip in quality for these tasks, but this will balance out once you learn how to successfully combine model types to suit the task at hand.
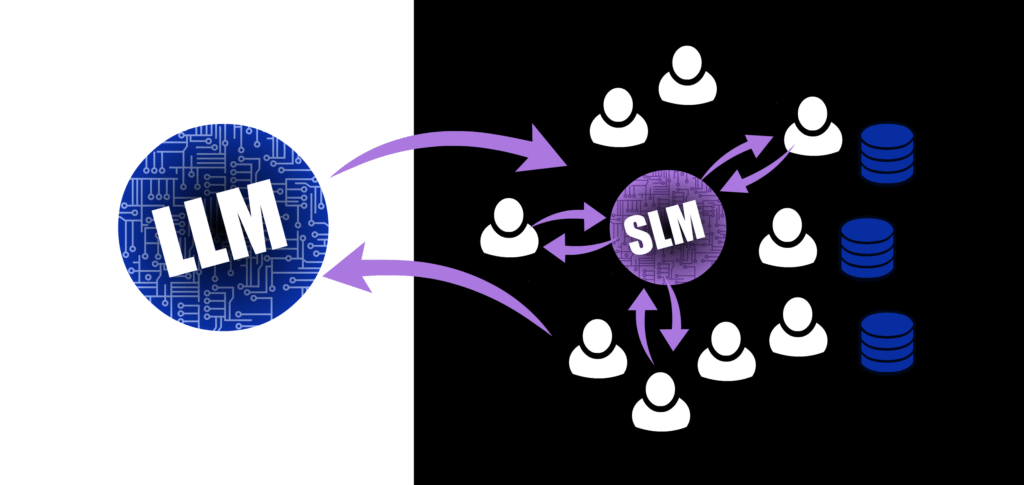
Figure 2: A good first move is a combination LLM and SLM; run the generic tasks off-site, running inference on the commercial systems, and the sensitive ones at home, even if there’s a minor quality difference. This makes it a far more secure system for all users.
Finally, evolve to a system of multiple, specialized, tuned SLMs that each reside on top of its own data source. This is the safest place for it to live, since the fewer trips a data-run needs to make, the better.
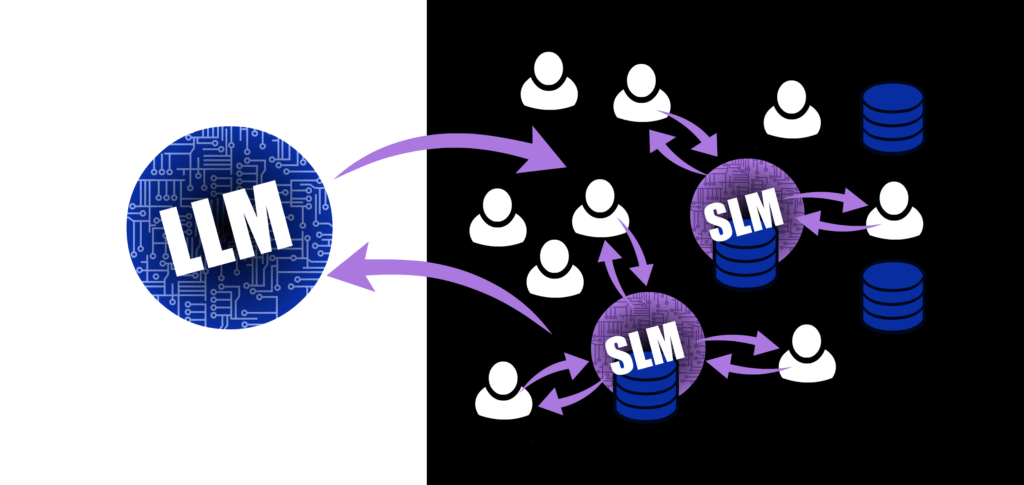
Figure 3: Finally, transition to a system that employes multiple SLMs with own data sources (and fine-tuning) baked in. While you are still using Frontier models to do some heavy lifting for generic tasks, the sensitive matters are now further built out and robust.
Need help with AI Integration?
Reach out to me for advice – I have a few nice tricks up my sleeve to help guide you on your way, as well as a few “insiders’ links” I can share to get you that free trial version you need to get started.

No eyeballs to read or watch? Just listen.
Working Humans is a bi-monthly podcast focusing on the AI and Human connection at work. Available on Apple and Spotify.

About Fiona Passantino
Fiona helps empower working Humans with AI integration, leadership and communication. Maximizing connection, engagement and creativity for more joy and inspiration into the workplace. A passionate keynote speaker, trainer, facilitator and coach, she is a prolific content producer, host of the podcast “Working Humans” and award-winning author of the “Comic Books for Executives” series. Her latest book is “The AI-Powered Professional”.
[1] “Quantized” means the AI model has been made smaller and faster by squeezing its parameters and weights into a simpler structure. It loses a little precision but runs much quicker and uses less memory. Think of compressing a photo so it loads faster without most people noticing the difference.
[2] “Inference” is when an AI uses what it has already learned to answer your question or make a prediction — basically, it’s the thinking part that happens after the training is done.